matplotlib, plt scatter 완벽 정리: 파이썬 머신러닝 판다스 데이터 분석(3)
안녕하세요, 매주한책입니다.
이번 포스트에서는 시각화 도구와 데이터프레임을 다루는 데 쓰이는 메소드를 정리하였습니다.
이 책을 읽으면서, 혼자 공부하는 머신러닝+딥러닝 책을 읽기 전에 이 책을 먼저 읽었으면 이해가 더욱 빨랐으리라 생각했습니다. 혼자 공부하는 머신러닝 책을 읽을 땐, 판다스와 데이터프레임에 대해서 잘 이해하지 못해서 코드를 읽기에 어려움이 있었는데, 파이썬 머신러닝 판다스 데이터 분석 책을 읽으면서 궁금했던 부분이 깔끔하게 해소됐습니다 ^^.
궁금증이 해소됐던 부분을 정리해보겠습니다.
데이터 분석을 하다 보면 시각화하여 데이터의 구조를 파악할 때가 있습니다.
이때 사용하면 좋은 것이 matplotlib입니다. matplotlib은 파이썬 표준 시각화 도구라고 부를 수 있을 정도로 그래프에 관한 다양한 포맷과 기능을 지원합니다.

파이썬 머신러닝 판다스 데이터 분석 요약
matplotlib plt 알아야 할 메소드 정리
matplotlib은 주로 plt로 약어를 설정합니다.
import matplotlib.pyplot as plt
plot() 메소드로 그래프를 그릴 수 있습니다.
차트 제목, 축 이름 추가하는 방법은 다음과 같습니다.
plt.title('차트제목')
#축 이름 추가
plt.xlabel('x 라벨')
plt.ylabel('y 라벨')
plt.show()
matplotlib 그래프 사이즈 설정하는 방법
figure() 함수로 그래프로 가로 사이즈를 더 크게 설정할 수 있습니다.
plt.figure(figsize=(14,5))
matplotlib 그래프 x축 라벨 수직으로 만드는 방법
xticks() 함수를 활용하면 x축 눈금 라벨을 반시계 방향으로 90도 회전합니다.
plt.xticks(rotation='vertical')그래프에 대한 설명을 추가하는 주석 넣는 방법
annotate() 함수를 사용하면 그래프 안에 주석을 넣을 수 있습니다.
여러 개의 그래프 한 번에 그리는 방법
axe 객체를 활용하면 한 번에 여러 그래프를 그릴 수 있습니다.
화면을 여러 개로 분할하고 분할된 각 화면에 서로 다른 그래프가 나타나기 때문에 비교할 때 사용하면 좋습니다.
fig = plt.figure(figsize=(10,10))
#2행, 1열, 1번째 부분
ax1 =fig.add_subplot(2,1,1)
ax2=fig.add_subplot(2,1,2)
#'o'옵션으로 점으로만 표시
ax1.plot(sr_one,'o',markersize=10)
#marker='o'옵션으로 원 모양의 마커를 가진 선 그래프
ax2.plot(sr_one, 'marker='o', markerfacecolor = 'green', markersize=10, color='olive', linewidth=2, label='서울 -> 경기')
#legend() 범례 표시
ax2.legend(loc='best')
#y축의 최소값 50000, 최대값 800000으로 설정
ax1.set_ylim(50000,800000)
ax2.set_ylim(50000,800000)
ax1.set_xticklabels(sr_one.index, rotation=75)
ax2.set_xticklabels(sr_one.index, rotation = 75)
plt.show()
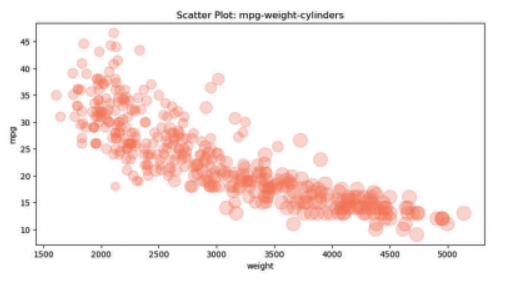
산점도
산점도(scatter plot)는 서로 다른 두 변수 사이의 관계를 나타냅니다.
데이터 값이 위치하는 x, y 좌표를 찾아서 점으로 표시합니다.
plot() 메소드에 kind ='scatter'옵션을 사용하여 산점도를 그릴 수 있습니다.
c='coral' 으로 점의 색상을 설정할 수 있고,
s=10으로 점의 크기를 설정할 수 있습니다.
df.plot(kind='scatter', x='weight',y='mpg', c='coral', s=10, figsize=(10,5))
plt.show()
s=cylinders_size로 설정하면, 값의 크기에 따라 점의 크기를 다르게 표시합니다.
데이터 전처리
누락 데이터 확인하는 방법
isnull() 메소드로 누락 데이터인지 파악 가능합니다.
#info()로 Non-Null값을 확인하여 NaN 파악 가능합니다.
df.info()
#isnull은 NaN값이면 True를 반환합니다.
missing_df = df.isnull()
for col in missing_df.columns:
missing_count = missing_df[col].value_counts()
try:
print(col, ':',missing_count[True])
except:
print(col,':',0)
누락 데이터 제거
누락 데이터가 있으면 머신러닝 모델을 만드는데 오류가 발생할 수 있어서 전처리가 꼭 필요합니다.
누락 데이터를 제거하는 방법으론 dropna() 메소드를 사용하면 됩니다.
thresh 옵션을 사용하면, NaN값이 임계값을 넘는 모든 열을 삭제합니다.
df_thresh = df.dropna(axis=1, thresh=500)
누락 데이터 치환
NaN 값이 있다고 무조건 삭제하면, 소중한 데이터를 활용하지 못합니다. 누락 데이터를 치환하는 방법이 있습니다.
판다스 fillna() 메소드를 사용하면 편리하게 처리할 수 있습니다.
fillna() 메소드는 새로운 객체를 반환하기 때문에 원본 객체를 변경하려면 inplace=True 옵션을 추가해야 합니다.
mean_age = df['age'].mean(axis=0) #age 열의 평균 계산 (NaN값 제외)
df['age'].fillna(mean_age, inplace=True)
데이터 반올림
데이터프레임의 데이터를 반올림하고 싶을 땐 round()명령을 사용하면 됩니다.
#kpl 열을 소수점 아래 둘째자리에서 반올림
df['kpl'] = df['kpl'].round(2)
데이터 타입이 object로 표시되는 경우
누락된 값이 '?'로 표시되는 건 아닌지 확인해보는 것이 좋다. '?'값이라면 '?'을 NaN으로 변경해주는 작업이 필요합니다.
NaN으로 바꾸고 난 다음에 dropna() 을 사용하여 NaN을 가진 행을 삭제해줍니다.
그다음에 astype() 메소드를 사용하여 자료형을 바꾸어주면 데이터프레임을 사용하기 적절해집니다.
df['number'].replace('?',np.nan, inplace=True)
df.dropna(subset=['number'],axis=0, inplace=True)
df['number']=df.astype('float') #문자열을 실수형으로 변환
'컴퓨터 IT > Python' 카테고리의 다른 글
| 파이썬 좌표 문제 입력 받는 방법(DFS, BFS) 퀵소트 코드 (0) | 2022.09.27 |
|---|---|
| 파이썬 좌표 문제 쉽게 해결하는 방법 (2) | 2022.09.21 |
| 이것이 취업을 위한 코딩 테스트다 파이썬 후기 (0) | 2022.09.19 |
| 코딩 테스트 준비: 파이썬 알고리즘 인터뷰 후기 (1) (0) | 2022.08.09 |
| Dataframe 기본 개념 정리: 파이썬 머신러닝 판다스 데이터 분석 (2) (0) | 2022.08.05 |